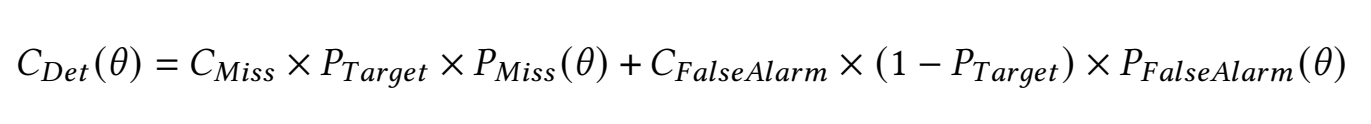


Welcome to the third Chinese Continuous Visual Speech Recognition Challenge, CNVSRC 2025!
The challenge aims to probe the performance of Large Vocabulary Continuous Visual Speech Recognition (LVCVSR) and Large Vocabulary Continuous Visual To Speech Conversion (LVCVTS)
Compared to CNVSRC 2024, this year we're offering (1) introduce a new visual to speech (VTS) track (2) release of additional 1,000 hours of training data, to support large-scale models.
The competition will be based on the CN-CVS, CNVSRC, CN-CVS2-P1, and CN-CVS3 datasets, totaling over 1,600 hours of data.
CNVSRC 2025 comprises two tasks: Multi-speaker VSR (T1) and Single-speaker VTS (T2). The former (T1) focuses on the accuracy of content recognition across multiple speakers, while the latter (T2) emphasizes the reconstruction of both content and speaker-specific audio characteristics under a single-speaker scenario.
The organizers provide baseline systems for participants to reference. Final results will be announced and awarded at the NCMMSC 2025 conference.
CNVSRC 2025 Evaluation Plan
Tasks
CNVSRC 2025 defines two tasks: Multi-speaker VSR (T1) and Single-speaker VTS (T2). In Task T1, participants are required to recognize the corresponding Chinese text from silent facial videos, whereas in Task T2, they are expected to reconstruct the original speech audio from the same type of silent facial video input.
Task 1. Multi-speaker VSR (T1)
The objective of this task is to assess the performance of the VSR system when it is applied to multiple speakers. In this task, both the data used for developing and evaluating the VSR system involve the same group of speakers. This group comprises multiple speakers, but each speaker has relatively limited data available.
For the T1 task, there are two defined tracks based on the data used for system development:
Fixed Track:ONLY the CN-CVS, CNVSRC(CNVSRC includes the CNVSRC.Single.Dev and the CNVSRC.Multi.Dev ), CN-CVS2-P1, CN-CVS3 dataset are allowed for training/tuning the system.
Open Track:ANY data sources can be used for developing the system, with the exception of the T1 evaluation set.
Task 2. Single-speaker VTS (T2)
The objective of this task is to evaluate the performance of a Visual-to-Speech (VTS) system in reconstructing speech audio from silent videos of a single speaker.
For the T2 task, there are two defined tracks based on the data used for system development:
Fixed Track:ONLY the CN-CVS, CNVSRC(CNVSRC includes the CNVSRC.Single.Dev and the CNVSRC.Multi.Dev ), CN-CVS2-P1, CN-CVS3 datasets are allowed for training/tuning the system.
Open Track:ANY data sources can be used for developing the system, with the exception of the T2 evaluation set.
Specifically, resources that cannot be used in the fixed track include: non-public pre-training models used as feature extractors, pre-training language models with more than 1B parameters, or that are non-public.
Tools and resources that can be used include: publicly available pre-processing tools such as face detection, extraction, lip area extraction, contour extraction, etc.; publicly available external models and tools, datasets for data augmentation; publicly available word lists, pronunciation dictionaries, n-gram language models, neural language models with less than 1B parameters.
Evaluation
Both tasks use Character Error Rate (CER) as the evaluation metric. For Task T1, CER can be directly computed from the predicted text. For Task T2, the generated audio is first transcribed into text using an ASR model, and then CER is calculated based on the transcription.CER is calculated by
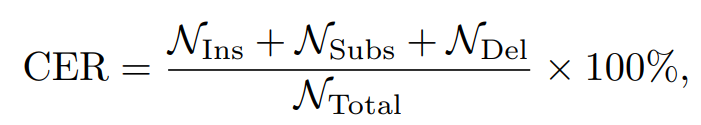
where NIns, NSubs, NDel are the character number of three errors, i.e., insertion, substitution, and deletion. NTotal is the total number of characters in ground-truth text transcription, which contains only Chinese characters.
License
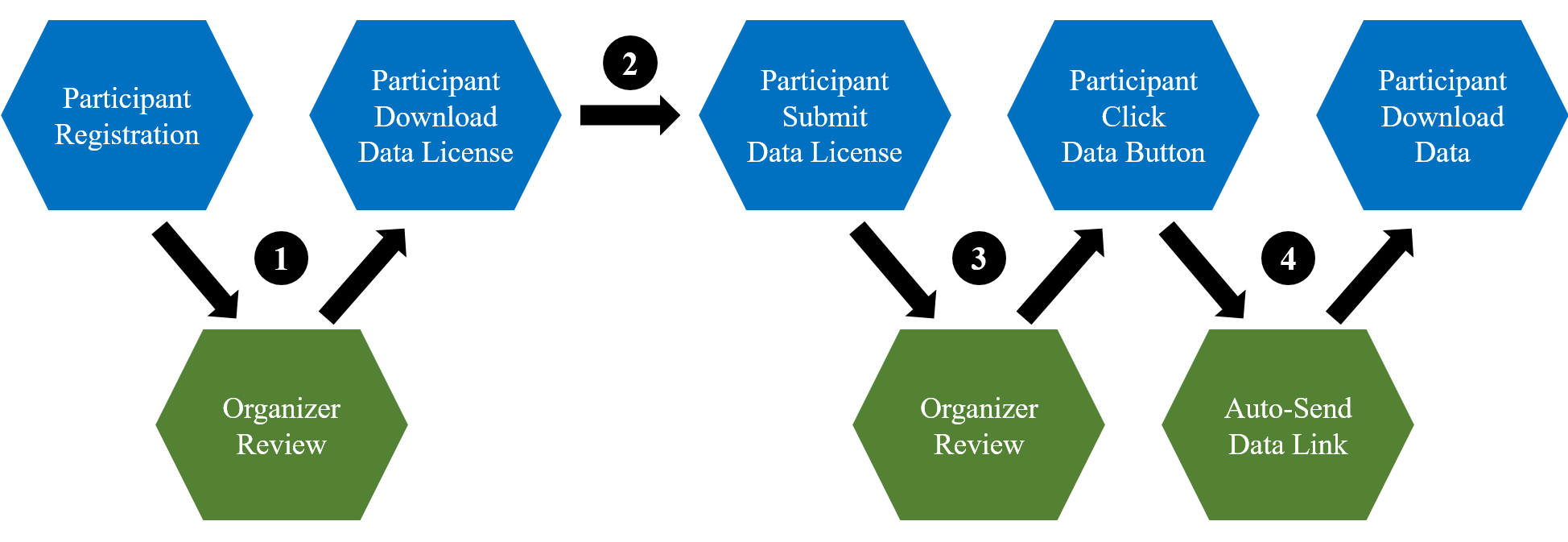
Participants can apply the data, by signing the data user agreement and upload it to the system.
The organizers will review the application. If it is successful, the data download links will be automatically sent to the email address provided during participants' registration.
Data
This challenge is centered around the CN-CVS dataset, which encompasses over 200,000 utterances from 2,557 speakers, with a total duration exceeding 300 hours.
Please click the button below to obtain the data and transcription of CN-CVS.
The organizers provide CN-CVS2-P1, the preview part of CN-CVS2 dataset, for system development.It encompasses over 160,000 utterances with a total duration about 200 hours.
Please click the button below to obtain the data and transcription of CN-CVS2-P1.
The organizers have also provided a new dataset, CN-CVS3. This is an additional data source specifically prepared for this year’s competition. It represents a significant expansion, containing over 900,000 utterances with a total duration of approximately 1,000 hours. This large-scale visual-speech dataset, primarily collected from internet media, is intended to serve as a comprehensive resource for system development and training. Please click the button below to access the CN-CVS3 data and transcriptions.
Additionally, for each task, corresponding development sets will be made available to participants.
Task 1. Multi-speaker VSR
Two datasets are released: CNVSRC-Multi.Dev and CNVSRC-Multi.Eval.
CNVSRC-Multi comprises two parts: (1) Video data recorded in a studio setting from 23 speakers. (2) Video data collected from the Internet including 20 speakers.
Each speaker possesses approximately one hour of data. Two-thirds of each person's data make up the CNVSRC-Multi.Dev, while the remaining data make up the CNVSRC-Multi.Eval.
For the CNVSRC-Multi.Dev, audio-video recordings and text transcriptions will be provided, while for the CNVSRC-Multi.Eval, only video data will be available.
In the fixed track, ONLY the CN-CVS, CNVSRC(CNVSRC includes the CNVSRC.Single.Dev and the CNVSRC.Multi.Dev ), CN-CVS2-P1, CN-CVS3 datasets are allowed for training/tuning the system.
In the open track, ANY data sources and tools are free to utilize for system development, with the exception of CNVSRC-Multi.Eval.
Task 2. Single-speaker VTS
Two datasets are released: CNVSRC-Single.Dev and CNVSRC-Single.Eval.
CNVSRC-Single.Dev contains 25,947 utterances from a single speaker, with a total duration of approximately 94 hours. CNVSRC-Single.Eval contains 300 utterances from the same speaker, approximately 0.87 hours in total.
For the CNVSRC-Single.Dev, audio-video recordings and text transcriptions will be provided, while for the CNVSRC-Single.Eval, only video data will be available.
In the fixed track, ONLY the CN-CVS, CNVSRC(CNVSRC includes the CNVSRC.Single.Dev and the CNVSRC.Multi.Dev ), CN-CVS2-P1, CN-CVS3 datasets are allowed for training/tuning the system.
In the open track, ANY data sources and tools are free to utilize for system development, with the exception of CNVSRC-Single.Eval.
Participation Rules
- Participation is open and free to all individuals and institutes.
- Anonymity of affiliation/department is allowed in leaderboard and result announcement.
- Consensus in data user agreement is required.
Registration
Participants must register for a CNVSRC account where they can perform various activities such as signing the data user agreement as well as uploading the submission and system description.
The registration is free to all individuals and institutes. The regular case is that the registration takes effect immediately, but the organizers may check the registration information and ask the participants to provide additional information to validate the registration.
Once the account has been created, participants can apply the data, by signing the data agreement and upload it to the system. The organizers will review the application, and if it is successful, participants will be notified the link of the data.
To sign up for an evaluation account, please click Quick Registration
Baseline
The organizers construct baseline systems for the Multi-speaker VSR task and the Single-speaker VTS task, using the data resource permitted on the fixed tracks. The baseline leverages advanced methods for VSR and VTS and offer reasonable performance, as shown below:
| Task | Multi-speaker VSR | Single-speaker VTS |
|---|---|---|
| CER on Dev Set | 31.91% | 33.15% |
| CER on Eval Set | 31.55% | 31.41% |
Participants can download the source code of the baseline systems from [here]
Submission and Leaderboard
Participants should submit their results via the submission system. Once the submission is completed, it will be shown in the Leaderboard, and all participants can check their positions. For each task and each track, participants can submit their results no more than 5 times.
All valid submissions are required to be accompanied with a system description, submitted via the submission system. All the system descriptions will be published at the web page of the CNVSRC 2025 workshop. The submission deadline for system description to CNVSRC 2025 is 2025/10/01, 12:00 PM (UTC). The template for system description can be downloaded [here].
In the system description, participants are allowed to hide their name and affiliation.
Dates
| 2025/07/04 | Registration kick-off |
| 2025/07/04 | Data release |
| 2025/07/04 | Baseline system release |
| 2025/08/01 | Submission system open |
| 2025/10/10 | Deadline for result submission |
| 2025/10/16-19 | Workshop at NCMMSC 2025 |
Organization Committees
DONG WANG, Center for Speech and Language Technologies, Tsinghua University, China
LANTIAN LI, Beijing University of Posts and Telecommunications, China
ZEHUA LIU, Beijing University of Posts and Telecommunications, China
XIAOLOU LI, Beijing University of Posts and Telecommunications, China
KE LI, Beijing Haitian Ruisheng Science Technology Ltd., China
HUI BU, Beijing AIShell Technology Co. Ltd., China
![]()



Please contact e-mail cnvsrc@cnceleb.org if you have any queries.
Acknowledgements
This work is supported by the National Natural Science Foundation of China (NSFC) under Grants No.62171250 and No. 62301075.
Special thanks to Beijing Haitian Ruisheng Science Technology Ltd for their generous donation of Chinese lip recognition video datasets to support CNVSRC.
